What Is Research Data Management (RDM) for 2026?
Co-Founder and Chief Data Scientist
Data preparation continues to account for a substantial portion of a researcher’s workload, often requiring more time than the analytical phases themselves. Recent evidence suggests that researchers and data professionals spend a significant share of their time cleaning, organizing, and validating datasets before meaningful analysis can begin (WiFiTalents, 2025). This extensive effort can divert attention from core research activities such as interpretation and hypothesis testing, and in some cases, it may even pull team members away from their primary roles to ensure data quality and usability.
While data is indeed one of the most—arguably the most—important parts of the research process, there is absolutely no need to dwell on data consolidation more than necessary. Handling research data is, thus imperative to the continuity and veracity of research work.
To that end, research data management (RDM) is a discipline concerned with making data—generated in the course of research—to be accessed as easily as possible by peers, contributors, and readers. This article plans to outline what it is, what it can do, and how to make an effective RDM plan.
Research Data Management Table of Contents
- Overview of RDM
- Benefits of RDM
- Can formal training enhance your research data management effectiveness?
- What are the legal and ethical considerations in research data management?
- Data Management Planning
- What are the common pitfalls in research data management?
- Can effective research data management boost your career prospects?
- How can automation and digital tools optimize research data management?
- How can you measure the effectiveness of your research data management strategy?
- What are the best resources to enhance your research data management skills?
- Manage Your Research for the Future
- The Impact of Data Ownership on the Research Process
Overview of RDM
In the scope of this article, we will refer to research data as simply “data," which, more specifically, refers to digital forms of data unless otherwise specified. But what is data, really?
What Is Data?
In general, data is information that is collected and recorded for later reference or analysis. It is important to recognize that data can be generated at any stage of academic research; however, without proper documentation, it may ultimately lose its value. Research data are more recently defined as recorded information—regardless of form or medium—that are collected, observed, or created to support, validate, and reproduce research findings (University of Wales Trinity Saint David, 2025; Nanyang Technological University, 2025).
They further subdivide research data into 4 types, as you can see in the graphic below.

Data can be extracted in a variety of ways. Most readers would automatically assume that data is natively digital, but in fact, digital is only one of the latest entrants to the data sphere. Scientists and researchers prior to the computer age have recorded their research data on other formats, such as:
- paper (e.g. notebooks and journals)
- images (e.g. photographs, scans, and/or film)
- audio (tape or otherwise)
- surveys
- lab equipment measurements
- samples
In addition, remember that “data" means differently among various disciplines. The fact remains, however, that recording data efficiently—meaning you devote less time preparing it—and making it accessible to peers and readers are the best ways to draw value from research. Research data management, or RDM, is a body of knowledge that seeks to do so.
Research Data Management: A Definition
Research data management describes a way to organize and store the data that a research project has accumulated in the most efficient way possible. It manages data gathered during the entire lifetime of the research project by coming up with consistent conventions. It is also responsible for the sharing, access, preservation, and secure disposal of data, thus making it an integral component of the various types of resource management. And, the practice is also intertwined with the tools that allow scientists to do so. Primarily, this involves the use of scientific data management system solutions.
Importance of RDM
There are several reasons RDM is important, apart from the obvious, which is to make data collection easy and efficient. Here are some:
- Data is a transient product and can be easily lost if not saved properly.
- Managing research data correctly saves time and money.
- Data that can be referenced, verified, and validated increases the accuracy and quality of the research. Sharing data can also often lead to developments and insights from its readers, even if they are outside the original research team.
- Managing research data plays a crucial role in identifying and correcting errors, particularly when datasets are accessible to the entire research team. Recent findings indicate that while data quality issues are common across research projects, many organizations still lack robust data governance and error-detection mechanisms, limiting their ability to effectively address these problems (WiFiTalents, 2025).
- Funding agencies increasingly turn to data and reproducible results to approve research grants.
Challenges in RDM
Like anything else, managing research data has several challenges. The following are the biggest:
- Improper storage of data. This can lead to data being disposed of carelessly or become unusable. This is one of the biggest issues in data handling, which is directly caused by the research team’s negligence. Depending on the terms of the agreement with the funder and/or sponsor, unusable data may actually be a violation. Plus, without proper data handling, inconsistencies will be overlooked.
- Failure to document technical data. Related to the first, this is a grave issue that stems from the team deviating from the proper standards of data documentation. This will make the findings of the research irreproducible, as any work that seeks to replicate the research will be riddled with inconsistencies.
- The research institution gets no copy of the data. Though rare, this is a big problem nonetheless if the original research team has left the institution and leaves them with no copy of the data. If later publications request access to the data—either to validate or recheck the findings of the report—it will put the institution in an awkward position. Maintaining data elsewhere, such as personal servers, also presents problems, including legal ones.
Sources of Research Data
In general, there are five main sources of data belonging to the primary and secondary research methodologies, as explained below. Note that the source of research data influences how any team manages that data. For example, observational data should be recorded right away to prevent data loss, while reference data isn’t as time-sensitive.
- Observation. This is data collected using observation of activity or behavior, usually through physical observation, surveys, or other sophisticated equipment like motion sensors. As explained above, this data needs real-time documentation as it is impossible to “redo" or recapture again if not recorded.
- Derivation. This uses existing data to arrive at another piece of data, through extrapolation, interpolation, transformation, or some other method. An example is using available data from observation (from the aforementioned motion sensors) to get to a conclusion, such as traffic volume. Unlike observational data, it can be redone, but it would cost a lot of time and resources to do so.
- Experimentation. This is what comes to most people’s minds when faced with the term “research data." This is data that a researcher collects by changing variables to measure or look at differences in a hypothesis. This is particularly useful to find a cause-and-effect relationship and can be used via statistical projection to apply to a larger set. This is more reproducible than either observational or derived data, but still expensive.
- Simulation. Here, a test model is used to imitate a process or a system over time to find what would or could happen in several conditions. This model is often a computer-generated one, but researchers have simulated tests before using good old-fashioned pen-and-paper. Test models run the gamut of real-world systems, such as weather, geological activity, financial markets, neural pathways, chemical reactions, among others. What sets a simulation data apart is that the test model is usually more important than the test data. Depending on the type of model, simulation is a more affordable data source, though somewhat limited to the accuracy of the model—which is itself a conglomeration of data from other sources.
- Reference. Reference data, also called canonical data, is a type of secondary data source. This is a collection of smaller data sources, such as those above, or those already published and reviewed and are open for access or later research. Peer-reviewed journals, gene sequence databanks, or open-source code are some examples of reference data.
Data Collection Methods
Whatever the source, researchers collect data using one of two types of research methods: qualitative and quantitative. As you can surmise from the name, qualitative is descriptive, which is useful for things that can be observed but not measured. Quantitative, meanwhile, regards numbers.
That said, the source or type of data means either method is much better suited. Language data for use in natural language processing, for example, cannot be measured, so it is more appropriate for a qualitative collection method (which brings us full circle as NLP can also automate qualitative data analysis, as Crowston [2011] pointed out in his paper).
The two methods are explained below.
Qualitative
Qualitative research is research that defines the associations of individuals and experience against a greater context, such as social realities or the world. It is more concerned with observing people and groups and how they live their lives in a particular setting. Therefore, qualitative research collects data that is more descriptive than empirical.
Qualitative data can be collected through a wide range of empirical methods, including interviews, observations, document analysis, visual materials, and personal experiences. Contemporary sources emphasize that qualitative data are not limited to textual formats; they also include non-textual forms such as photographs, video recordings, and audio files, all of which can provide rich, contextual insights into human experiences and social phenomena (SAGE Publications, 2025). For example, an anthropologist documenting oral histories through recorded interviews is engaging in a form of qualitative data collection that captures both narrative content and cultural context.
Qualitative research provides insight into how individuals experience their world and how they behave within their social contexts. It emphasizes meaning, interpretation, and lived experience rather than numerical measurement. However, it is important to recognize that the individuals involved in producing the data—whether researchers, participants, or annotators—play a critical role in shaping the outcomes. Because perspectives, contexts, and interpretations can vary, qualitative data are generally considered subjective and are understood in relation to the observer (Simply Psychology, 2025).
This subjectivity, however, is also one of the key strengths of qualitative research, as it allows researchers to gain a deeper, more nuanced understanding of the subject matter—often comparable to an insider’s perspective. Such close engagement provides access to subtle cues, meanings, and contextual details that are frequently overlooked in quantitative approaches. Moreover, qualitative methods enable researchers to capture contradictions and ambiguities within the data, offering a more realistic reflection of complex human experiences and social realities (SAGE Publications, 2025).
Quantitative
On the other hand, quantitative research is generally considered more objective because it relies on established standards of reliability and validity through numerical measurement. While not all phenomena can be captured in this way, quantitative data offer the advantage of being easily categorized, compared, and ranked for various analytical purposes, including graphs, charts, and tables. This capacity for visualization allows researchers not only to present data but also to clarify patterns and support conclusions in a more interpretable manner (IBM, 2025).
The primary goal of quantitative researchers is to develop generalizable frameworks that can be applied across different settings and purposes, often through structured experimentation. To control for extraneous variables, these experiments are typically conducted in controlled environments, such as laboratories. However, this approach can constrain the resulting data, as it is influenced by the specific context of the study, including the assumptions, limitations, and expertise of the researcher (WiFiTalents, 2025).
Benefits of Research Data Management
Research data management offers a lot of benefits to researchers. Some of these are discussed below.
Data Security
The most important benefit of RDM is that you can secure your data. By making an effective research data management plan, you minimize data loss and unauthorized access by adhering to data storage or organization standards. You also reduce the risk of losing the integrity of data either through accident or negligence.
The most common site to store your research data is in your institution’s repository, like servers (for digital data). Your institution or organization may have advice on where to store your data. Note that many funders generally dislike storing research data that they funded on personal repositories or elsewhere, especially without authorization.
Efficient Collaboration
The second major benefit of research data management (RDM) is enhanced collaboration, which is increasingly important as research projects grow in complexity and involve multiple contributors. Studies show a positive correlation between the number of authors on a publication and its impact compared to single-author works. Making data accessible not only to all team members but also to other researchers within the same discipline can create significant opportunities to advance one’s own research and foster broader scientific progress (WiFiTalents, 2025).
Plus, good RDM routines also improve the efficiency of data access. An organized data directory structure, for example, can make contributing data or building upon the existing dataset much easier. Efficient data organization also makes keeping tabs on the progress of the project much more seamless and puts accountability front and center.
Reproducibility of Research
If another team uses the data you generated to try to replicate your research, strong research data management practices help ensure they can arrive at the same results. Good RDM enhances research integrity by making methods and datasets available in sufficient detail for others to verify, repeat, and reproduce your work. Reproducibility also demonstrates that research findings are not due to bias or chance, which is vital for the accuracy and reliability of scientific results and for building confidence in the research community’s conclusions (Wellcome Open Research, 2025).
Openly sharing your research data can increase its visibility and the likelihood of citations. Recent evidence shows that, in large datasets of publications, practices like openly sharing data are correlated with higher citation counts compared with similar publications that do not share data, suggesting that making data available contributes to broader scholarly impact (Colavizza et al., 2025). Proper data citation standards—including using persistent identifiers like digital object identifiers (DOIs)—help ensure that datasets are traceable, reusable, and credited appropriately across the research ecosystem, enhancing transparency and discoverability for both data and associated publications (DataCite, 2025; U.S. Geological Survey, 2025).
Can formal training enhance your research data management effectiveness?
Formal training in research data management equips researchers with up-to-date technical and regulatory knowledge that is critical for maintaining data integrity and security. Through structured coursework and certifications, professionals gain insight into advanced tools, data governance frameworks, and ethical standards that drive operational excellence. Additionally, acquiring specialized skills can foster smoother interdisciplinary collaboration and ensure compliance with evolving data policies. For further educational opportunities, consider exploring the best online certificate schools to deepen your expertise and support your research ambitions.
What are the legal and ethical considerations in research data management?
Robust research data management requires adherence not only to technical standards but also to legal and ethical imperatives. Researchers should ensure compliance with relevant data protection regulations—such as GDPR and HIPAA—by implementing rigorous privacy safeguards and obtaining informed consent when needed. Regular review of institutional policies and ethical guidelines minimizes legal risks and supports transparency in data sharing and licensing. Audited protocols and documented consent processes further protect intellectual property and research participants' rights. Interested professionals can bolster their expertise by exploring advanced interdisciplinary programs at universities that offer dual master's degrees.
Data Management Planning
Knowing why you should manage your research data is all well and good, but the question remains: how should you do it? The answer is that you start with a data management plan, or a DMP, which will cover how your files and datasets are stored, organized, and arranged in a database. There are several database formats, which you can use for huge volumes of data, but if you only need to array them that makes the most sense in a computer, you can find a few tips below.
Before you begin, you need to make many decisions on how to manage your data. For example, funders now require an outline of your data management plans even before you begin your research, along with how regularly you need to furnish them with this data, needed hardware and other equipment, and other issues. This is an ideal starting point to make a DMP as a map to all your planned research data—whether your funder requires it or not.
Additionally, you’ll have to contend with other considerations. Some of them include:
- Funder’s policies and expectations
- Copyright, intellectual property, and privacy issues
- Data format
- Data quantity
- Data storage (hardware and supporting software)
- File naming and directory structure conventions
- Version control, if necessary
- Access and sharing permissions
- Team roles
- Budget
We look at these considerations further below. This is especially useful for researchers who want to outline a more specific approach on how to organize and simplify their research data management.
Organizing Data
Consistency and logic are the top two reasons researchers organize their data. It allows any member of the team to find and use them easily. You need not create a highly detailed flowchart for this, however, as it may simply entail thinking about a file naming convention and how to nest them in your directories for easy access. The ideal time to do this is before the project or the research begins.
Naming conventions also preclude the possibility of overwriting files. File names may contain dates and other identifiers to help you track which files are yours and when they were modified. Metadata, however, is much more accurate for this task, which we’ll also cover below.
For reference, the Library of Congress has recommended formats for data and databases on this page: https://www.loc.gov/preservation/resources/rfs/data.html.
Structure and Hierarchy
As mentioned, structuring your datasets in files and folders is an easy way to start your data management plan. Here are some ideas to get you started:
- Place files in the appropriate folder. Much like in real life, you would want to place files pertaining to a specific subject or topic in one folder.
- Use hierarchy. Use a few folders at the top for broader subjects, then more subfolders as needed for more specific topics.
- Check for existing practices. If your team or institution already has a file structure and naming convention, see if you can adopt it so you don’t have to start from scratch.
- Stick to convention. In any case, stick to your file naming convention to prevent confusion, especially for newcomers to the team or the workspace.
- Archive completed work. To streamline your work further, make sure superseded data is archived, not replaced completely. It may be useful to look at older iterations of research, such as to check for anything you might have missed. The important thing is to separate ongoing data from everything else.
- Maintain a backup. Your data should be backed up, whether they are primarily saved on your local hard drive, on your intranet, or on the cloud. Your backups should have a backup, which means cloud storage, which syncs automatically with files on your local machine, is a great option.
As for files, agree with your team on how to properly label files so you don’t confuse one another when labeling them. It is a good idea to opt for a version control naming scheme, for example, a “v01" or “v02" appended on the file name. In many cases, a final version of the file with the data in question can be marked as “final." The one who will likely do this is the supervisor, the principal investigator, or the approver of the research.
Metadata
Metadata means data about data. This is information that tells you about the data contained in a file, which is helpful to find the exact file you are looking for (and for others too). At present, not only does metadata define data but it is also useful in bridging connections among tools and software, like an API.
Metadata contains information that is necessary to find, interpret, and use your file, folder, or data. Like your file naming and folder structure conventions, deciding on metadata should be done at the start of the project.
There are generally two ways to attach metadata to your files: embedded metadata and supporting metadata.
Embedded Metadata
This means embedding information into the file itself using various means. This is the easiest, both for the creator of the file and those trying to find it. There are various ways to do this. Some embed metadata into the file itself using XML text, such as this:
<data camera="b" date="14-Jun-01" direction="left" filename="021b001.dv" session="021" start_frame="335" start_time=" 0:00:13.10" stop_frame="4914" stop_time=" 0:03:16.14" subject_id="001" xmlcreatedby="xmlwrite.py; Time Code for segments added" xmlcreatedon="Tue Mar 26 15:32:05 2002"> <data camera="b" date="14-Jun-01" direction="left" filename="021b001.dv" session="021" start_frame="335" start_time=" 0:00:13.10" stop_frame="4914" stop_time=" 0:03:16.14" subject_id="001" xmlcreatedby="xmlwrite.py; Time Code for segments added" xmlcreatedon="Tue Mar 26 15:32:05 2002"> <comments> No comment </comments> <segments automatic="no" checked="yes"> <fullview> <start frame="51" start_frame="1104"/> <stop frame="2771"/> </fullview> <postbackground> <start frame="2772" start_frame="4867"/> <stop frame="2822"/> </postbackground> <prebackground> <start frame="0" start_frame="335"/> <stop frame="50"/> </prebackground> </segments> </data>
Some operating systems also support embedding of metadata this way, such as Microsoft’s Document Properties.
Other ways to embed metadata include descriptions, such as on the code or labels within the file itself. Some users also embed metadata using headers or summaries.
Supporting Metadata
This metadata is separate from the main datasets, and are often used in accompaniment with it. These are sets of documents that contain an explanation or context of the data they are trying to support (hence the name), much like an operating manual.
The main disadvantage of supporting metadata is that they run the risk of being as voluminous as the main dataset they prop up. In this case, best practices in structuring and naming, as explained above, also apply.
Data Sharing and Preservation
Data will outlive the project, so you should plan for ways to share and preserve your data for posterity. Data preservation is part of the research data lifecycle. Though there are slightly varying models of data lifecycles, the research data lifecycle involves the movement of data from creation to preservation and reuse, ad infinitum.
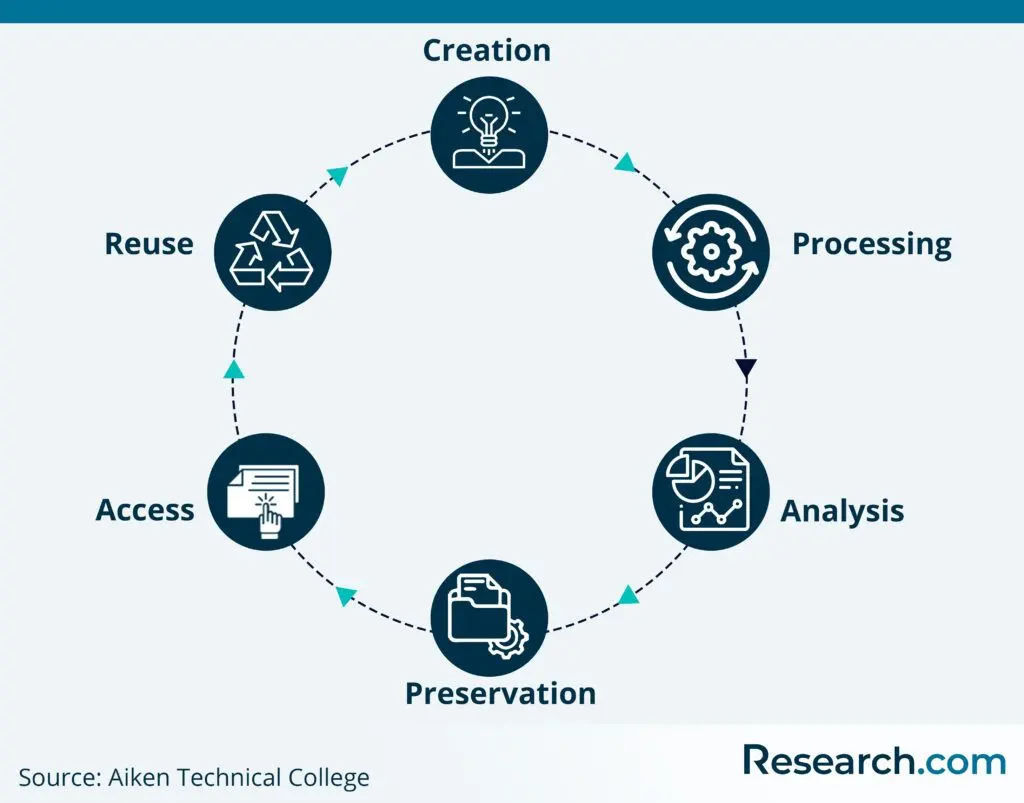
Digital data has an advantage in the sense that it can be maintained for far longer than other types. However, the main drawback to this is that as technology progresses, the tools meant to access this data may change. Good RDM practices, thus plan for this inevitability by ensuring all data can be understood and used even years down the line.
Preserving data, however, does not mean merely saving to backups. As mentioned before, you should future-proof your data using these practices.
- Migrate to newer storage media periodically, across a variety of formats.
- Have backups of backups (and migrate them too).
- Use metadata.
- Use file formats that can be accessed by as many programs as possible or can be imported easily across formats.
- Update firmware on your storage media, if possible.
- Have “hard" copies of data, if possible.
Sharing and Licensing
Data should not be siloed, and research data even more so. There is no sense to hoard data, after all. Sharing is not only a good source of feedback but it is also a way to increase funding interest, garner citations, and build reputation.
Researchers can share data using a variety of means. At its simplest, you can store them in a USB flash drive, which can be borrowed by colleagues. Otherwise, you can use FTP upload on a server, such as to your institution’s repository. Another way includes cloud sharing, which is explained below.
As for licensing, investigators can simply make a request form that anyone who wants to use their data can fill out. Otherwise, if internet publication is preferred, Creative Commons licenses are ideal for research work. Though there are many types of CC licenses, the most appropriate for research data is the “By-Attribution, Non-Commercial" license, which states that anyone can use the data in a researcher’s work as long as they cite their source/s and they avoid using it for profit. Some states or territories, however, have conflicting assessments of the NC clause, so check with the licensing authority first.
And what is even better is that CC licenses do not need paperwork to be filed; you just need to notify your readers or other interested parties that you’re using a particular type of Creative Commons license. However, CC licenses are irrevocable. Use it only when you are certain that you will not revoke it in the future for any reason.
Backup
Data loss is the enemy of nearly every researcher—or near everyone who has stored files in any kind of storage medium. This is why it is crucial to have backups of your data, and to even backup your backup if necessary.
Some institutions often use automatic backups to periodically save research work or any materials stored in their repositories. Ask your computer or network administrator for details of this automatic procedure, especially how often it happens, where it is stored, and how long the backups are kept. In any case, no matter how exemplary your institution’s backup process is, it is still prudent to back your data up on your own.
Cloud storage provides a relatively affordable but highly reliable means of backing up data. In addition, they offer competitive cost-to-space ratios. No matter the cloud provider, though, cloud storage syncs in real-time, so your remote backup data is updated as soon as yours do.
Whatever the case, it’s a good idea to diversify your backup formats and locations so you can keep data as safe as possible.
How does data ownership impact the research process?
Data ownership is an important but often overlooked aspect of research data management. It involves determining who has control over the data collected during the research process, who can access it, and how it can be used in the future. Properly addressing data ownership is essential for ensuring ethical research practices and avoiding conflicts later on. Here are key points to consider regarding data ownership:
- Legal implications and intellectual property: Data ownership determines who has the legal rights to the research data. This includes the right to publish, share, or commercialize the data. In cases where research is funded by external organizations or government grants, ownership might reside with the funding agency rather than the researcher.
- Institutional policies: Research institutions often have policies governing data ownership, especially when research is conducted under their auspices. Researchers should be aware of their institution’s policies to ensure compliance, particularly regarding data storage, sharing, and archiving.
- Collaboration agreements: In collaborative research projects, clear agreements about data ownership need to be established upfront. This helps avoid disputes over data usage, especially when multiple researchers or institutions are involved in generating or analyzing the data.
- Data sharing and future use: Ownership impacts whether and how data can be shared with third parties. Clear guidelines on who controls data sharing are essential for maintaining trust and transparency in research.
What are the common pitfalls in research data management?
A frequent oversight in research data management is the absence of rigorous quality assurance protocols. Incomplete or inconsistent metadata, poorly defined file naming conventions, and fragmented organizational structures can considerably compromise data discoverability and reproducibility. Additionally, inadequate backup procedures and weak security measures increase the risk of data loss and unauthorized access. Researchers must also address compliance gaps by staying informed on evolving regulatory standards and integrating ethical, legal, and technical safeguards into their workflows. Proactively identifying and mitigating these risks solidifies data integrity and enhances the long-term impact of research initiatives—resources explaining what is the easiest degree to get may offer additional insights into foundational strategies.
Can effective research data management boost your career prospects?
Developing expertise in research data management not only strengthens research integrity but also opens pathways to diverse, high-demand career opportunities. Proficiency in organizing, curating, and preserving data is increasingly valued by academic institutions and industry leaders alike, positioning professionals advantageously in roles that require technical acuity and strategic planning. Mastery of robust RDM practices enhances one’s credibility, fosters interdisciplinary collaboration, and supports leadership in data-driven environments. In addition, such skills are recognized as a key differentiator in competitive fields, including those found within majors that make the most money, where data handling and analysis are critical.
How can automation and digital tools optimize research data management?
Rapid digital transformation has positioned automation and specialized digital tools as critical components in research data management. Leveraging automated workflows—such as real-time data validation, metadata tagging, and version control—minimizes manual errors while accelerating collaboration and reducing turnaround times. In addition, integration of cloud-based solutions supports secure data backup and facilitates seamless access for interdisciplinary teams, thereby strengthening overall data integrity and reproducibility. For those seeking to advance their technical capabilities in this area, exploring courses at online schools with no application fee can provide valuable insights into effective digital integration and data governance.
How can you measure the effectiveness of your research data management strategy?
To ensure your research data management (RDM) approach is yielding tangible benefits, it is critical to establish clear performance metrics. Begin by defining quantitative Key Performance Indicators (KPIs) such as data accessibility scores, error rates in datasets, and compliance rates with institutional and regulatory standards. In tandem, qualitative assessments through user feedback and peer reviews can offer insight into the efficiency and transparency of your data practices. Regular audits to track adherence to metadata standards and version control protocols will further highlight areas for improvement. Lastly, align your strategy with broader academic and professional benchmarks to gauge progress, and invest in advanced training—consider a 1 year masters program—to stay abreast of evolving best practices in RDM.
What are the best resources to enhance your research data management skills?
Advanced research data management demands continuous learning through formal training, peer mentorship, and practical exposure. Specialized workshops, certifications, and targeted online courses can build proficiency in areas such as metadata creation, secure data storage, and regulatory compliance. Leveraging digital platforms helps professionals stay updated on evolving best practices and emerging technologies. Consider programs offered by affordable online universities for working adults that accommodate working professionals seeking to expand their expertise without compromising their current commitments.
Manage Your Research for the Future
It can be said that good data management is not the destination, but the journey; it is how researchers lead to discovery and innovation. Data, freely shared, can lead to further insights long after the original project is done and the research team has moved on.
This is why it is important to have a logical data management system to index and store your research data, not only for your own use but for those who will come after. Citation is an essential part of the research environment, which brings your findings to the experts who can build on your work. Using initiatives like the DOI and new technologies, such as cloud storage can bring your research to more minds than ever before.
To do that, however, managing your data just as your predecessors did is still a good idea. Following conventions, practicing logical data structure, and citing wisely is the framework upon which the future of science is built.
Key Insights
- Time-Intensive Process: Data preparation is a time-consuming aspect of research, often taking up significant portions of a methodologist's time and detracting from other research activities.
- Importance of RDM: Research data management (RDM) is essential for ensuring data accuracy, accessibility, and preservation. Proper RDM practices facilitate efficient data use, sharing, and reproducibility.
- Types of Research Data: Research data can be categorized into several types, including observational, derived, experimental, simulation, and reference data. Each type requires different management and documentation approaches.
- Challenges in RDM: Major challenges include improper data storage, failure to document technical data, and lack of institutional copies of data, all of which can lead to data loss and inconsistencies.
- Data Collection Methods: Data can be collected through qualitative (descriptive) and quantitative (numerical) methods, each suited for different types of research and analysis.
- Benefits of RDM: Effective RDM enhances data security, promotes efficient collaboration, and ensures the reproducibility of research, which is crucial for validation and future studies.
- Data Management Planning: Creating a data management plan (DMP) is critical. It includes considerations for data organization, storage, sharing, and preservation, ensuring data integrity throughout the research lifecycle.
References:
- Glaser, D. (n.d.) When Interpretation Goes Awry: The Impact of Interim Testing. David Streiner, Souraya Sidani (Eds.). When Research Goes Off the Rails: Why It Happens and What You Can Do About It (p. 327). Retrieved from https://books.google.com.ph/books?id=aljkTd9unTMC&pg
- Anderson, N., et al. (n.d.) Journal of the American Medical Informatics Association, Vol 14(4). Issues in Biomedical Research Data Management and Analysis: Needs and Barriers. (pp. 478-488). Retrieved from https://doi.org/10.1197/jamia.M2114
- Denzin N., Lincoln Y. The Discipline and Practice of Qualitative Research. Norman Denzin and Yvonne Lincoln (Eds.). Handbook of Qualitative Research (p. 14). Retrieved from https://www.sagepub.com/sites/default/files/upm-binaries/17670_Chapter1.pdf
- McLeod, S. (n.d.). Simply Psychology. Qualitative vs. quantitative research. Retrieved from https://www.simplypsychology.org/qualitative-quantitative.html
- Denscombe, M. (n.d.) The Good Research Guide: For Small-scale Social Research Projects (p. 319). Retrieved from https://www.academia.edu/2240154/The_Good_Research_Guide_5th_edition_
- Cleveland, W. (n.d.). Visualizing Data. Retrieved from https://dl.acm.org/doi/book/10.5555/529269
- Carr, L. (n.d.) Journal of Advanced Nursing, (20)4. The strengths and weaknesses of quantitative and qualitative research: what method for nursing? (p. 717) Retrieved from https://pdfs.semanticscholar.org/a87b/ce9f2d5fe771005a2890c92da2cff8a03b32.pdf
- Antonius, R. (n.d.) Interpreting Quantitative Data with SPSS. Retrieved from https://dx.doi.org/10.4135/9781849209328
- Markowetz, F. (n.d.) Genome Biology 16, 274. Five selfish reasons to work reproducibly. Retrieved from https://doi.org/10.1186/s13059-015-0850-7
- Piwowar, H., Vision, T., et al. (n.d.). Data reuse and the open data citation advantage. Retrieved from https://peerj.com/articles/175/
- Lamberts, J. (n.d.). Two Heads are Better than One: The Importance of Collaboration in Research. HuffPost. Retrieved from https://www.huffpost.com/entry/two-heads-are-better-than_1_b_3804769
- Sen, A. (n.d.). Metadata management: past, present and future. Decision Support Systems. Retrieved from https://doi.org/10.1016/S0167-9236(02)00208-7
- Ball, A. (n.d.) Review of Data Management Lifecycle Models. University of Bath, Bath, UK. Retrieved from https://researchportal.bath.ac.uk/en/publications/review-of-data-management-lifecycle-models(23c4ba4b-c694-4787-90e7-aa85ac6edf3a).html
- Hagedorn, G. et al. (n.d.). Creative Commons licenses and the non-commercial condition: Implications for the re-use of biodiversity information. Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3234435/.
- Wilkinson, M et al. (n.d.). The FAIR Guiding Principles for scientific data management and stewardship. Retrieved from https://www.nature.com/articles/sdata201618.pdf?origin=ppub
- WiFiTalents. (2025). Data science and analytics statistics 2025. https://wifitalents.com/survey-industry-statistics/
- University of Wales Trinity Saint David. (2025). Research data management policy. https://digitalservices.uwtsd.ac.uk/wp-content/uploads/2025/05/Research-Data-Management-Policy-2022-v2.pdf
- Nanyang Technological University. (2025). Research data management policy. https://www.ntu.edu.sg/research/research-integrity-office/research-data-management-policy
- SAGE Publications. (2025). Qualitative research methods. https://methods.sagepub.com/
- Simply Psychology. (2025). Qualitative research methods. https://www.simplypsychology.org/qualitative-research.html
- IBM. (2025). Quantitative data and analysis. https://www.ibm.com/topics/quantitative-data
- Wellcome Open Research. (2025, January 15). The importance of reproducibility in open research. https://blog.wellcomeopenresearch.org/2025/01/15/the-importance-of-reproducibility-in-open-research/
- Colavizza, G., Cadwallader, L., & Hrynaszkiewicz, I. (2025). An analysis of the effects of open science indicators on citations in the French Open Science Monitor (preprint). arXiv. https://arxiv.org/abs/2508.20747
- DataCite. (2025). Data citation. https://support.datacite.org/docs/data-citation
- U.S. Geological Survey. (2025). Data citation. https://www.usgs.gov/data-management/data-citation
Other Things You Should Know About Research Data Management (RDM)
Research data management (RDM) refers to the systematic organization, storage, sharing, and preservation of data generated during a research project. It ensures that data is accessible, accurate, and reusable.
RDM is important because it enhances the accuracy and quality of research by ensuring data is well-organized and accessible. It helps prevent data loss, promotes collaboration, and supports the reproducibility of research findings.
The main challenges in RDM include improper data storage, failure to document technical data, and lack of institutional copies of data. These issues can lead to data loss, inconsistencies, and difficulties in reproducing research results.
Research data is categorized into observational, derived, experimental, simulation, and reference data. Each type requires different methods for collection, documentation, and management.
Effective RDM improves data security, facilitates efficient collaboration, and ensures the reproducibility of research. It also helps spot errors and supports data sharing, which can lead to new insights and developments.
A DMP should include considerations for data organization, storage, sharing, preservation, and documentation. It should also address funder policies, intellectual property issues, data format, quantity, and team roles.













































